COVID-19 Sounds App
< Research Updates
We release our large-scale audio dataset to the research community
November 20, 2021 — Audio signals are widely recognised as powerful indicators of overall health status, and there has been increasing interest in leveraging sound for affordable COVID-19 screening through machine learning. However, there has also been scepticism regarding the initial efforts, due to perhaps the lack of reproducibility, large datasets and transparency which unfortunately is often an issue with machine learning for health.

To facilitate the advancement and openness of audio-based machine learning for respiratory health, we now release a dataset consisting of 53,449 audio samples (over 552 hours in total) crowd-sourced from 36,116 participants through our COVID-19 Sounds app. Given its scale, this dataset is comprehensive in terms of demographics and spectrum of health conditions. It also provides participants' self-reported COVID-19 testing status with 2,106 samples tested positive. To the best of our knowledge, COVID-19 Sounds is the largest multi-modal dataset of COVID-19 respiratory sounds: it consists of three modalities including breathing, cough, and voice recordings.
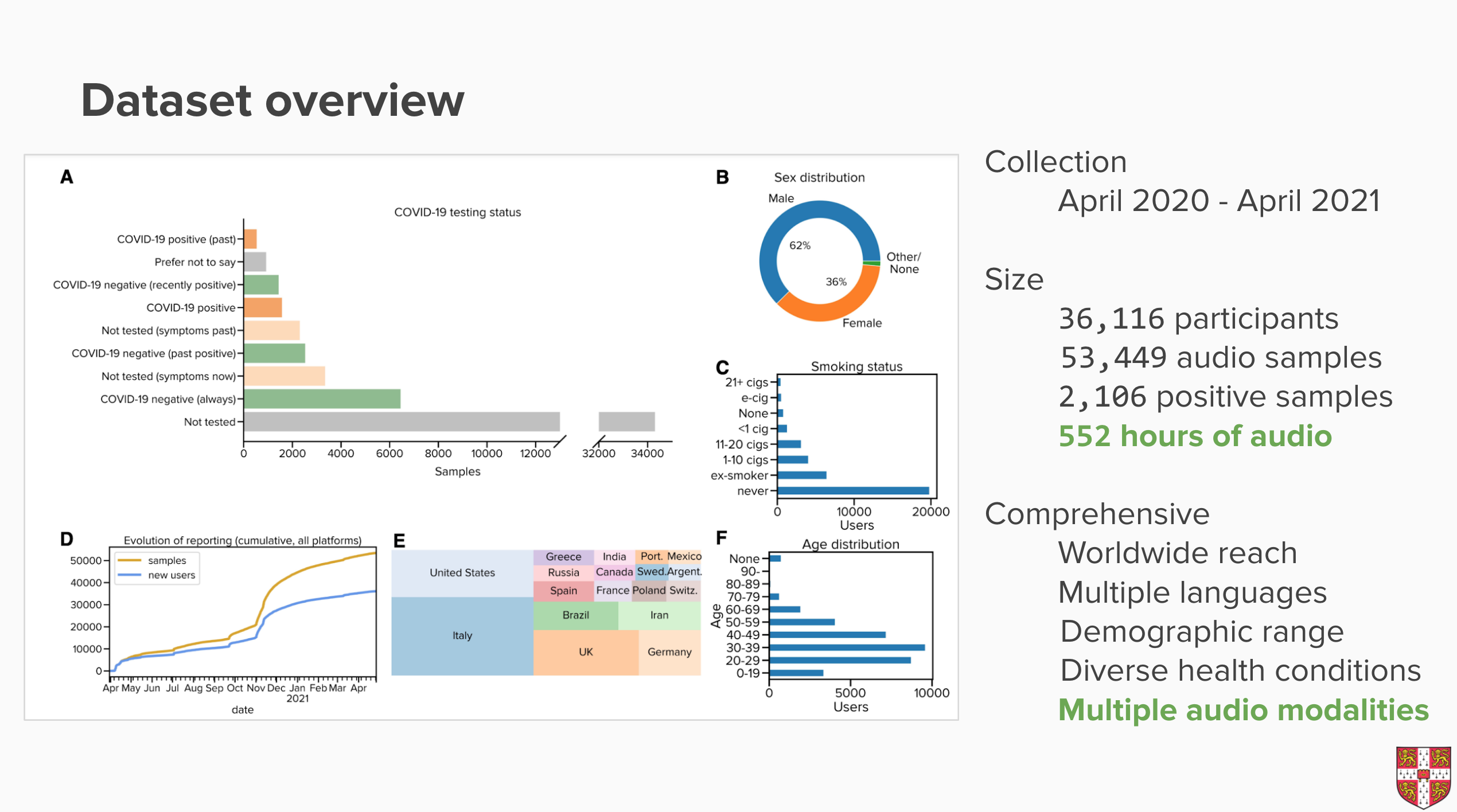
Our paper to describe more details about this dataset named: “COVID-19 Sounds: A Large-Scale Audio Dataset for Digital Respiratory Screening” has been accepted for publication at NeurIPS 2021 Dataset Track. Additionally, in the paper, we report on several benchmarks for two principal research tasks: respiratory symptoms prediction and COVID-19 prediction. For these tasks we demonstrate performance with a ROC-AUC of over 0.7, confirming both the promise of machine learning approaches based on these types of datasets as well as the usability of our data for such tasks. We describe a realistic experimental setting that hopes to pave the way to a fair performance evaluation of future models. We also reflect on how the released dataset can help to scale some existing studies and enable new research directions, to inspire and benefit a wide range of future work.
Due to the sensitive nature of the data involved, in order to gain access to the dataset, a Data Transfer Agreement (DTA) needs to be signed. The data can only be shared with academic institutions. To obtain access to the dataset, please send an email to the following address: covid-19-sounds@cl.cam.ac.uk . Enclose your institution and a brief introduction about how you plan to use this data. The DTA will need to be signed by the legal representative of your academic institution, and by a member of the academic staff. Once all the necessary legal steps have concluded on both sides, we will share the data folder by Google Drive through the Google account you provide. The folder we share contains: 1) metadata csv files, 2) all audio samples, 3) subsets used for benchmarks, and 4) an excel sheet for data format introduction.
We are looking forward to receiving your requests!
When you use this dataset, please cite our paper as follows:
Tong Xia^, Dimitris Spathis^, Chloë Brown*,
Jagmohan
Chauhan*, Andreas Grammenos*, Jing Han*, Apinan Hasthanasombat*, Erika Bondareva*, Ting
Dang*,
Andres Floto, Pietro Cicuta, Cecilia Mascolo.
"COVID-19 Sounds: A Large-Scale Audio Dataset for Digital Respiratory Screening."
Proceedings of
the 35th Thirty-fifth Conference on Neural Information Processing Systems Datasets and
Benchmarks Track (NeurIPS 2021)
[PDF].
^joint first authors, *equal contribution, alphabetical order